I’ve been playing with Stable Diffusion on my M1. The DiffusionBee app is a terrific way to immediately play with Stable Diffusion.
However, if I use anthing other than 512x512 for the image size, it bogs down my machine at best, and crashes the entire machine at worst.
So, I have been investigating upscaling, a process where a low-rez image is “upscaled” to produce a higher resolution image, but without quality loss. The fun thing about upscaling is that it produces an image where the lines are much more organic and lively, rather than simply doing a raw mathematical calculation to add pixels.
I did some research, and found a great video on upscaling, that promotes ChaiNNer.
https://github.com/joeyballentine/chaiNNer
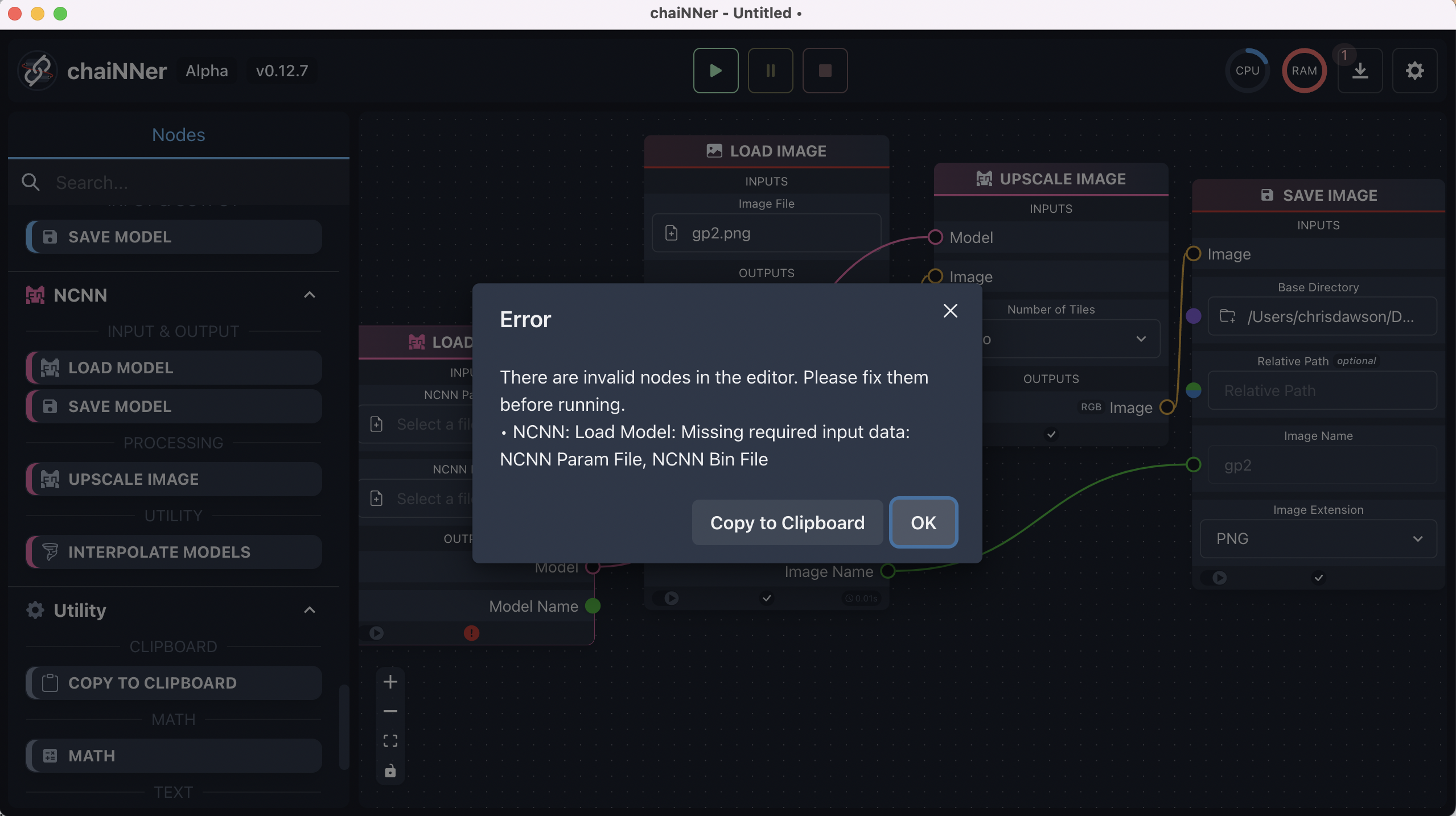
My results with using ChaiNNer were mixed. It certainly has a beautiful UI. However, attempting to install NCNN seemed to succeed, but no where in the UI did it tell me where and if the model weights were installed. I see in the screenshots that I should just be able to select the weights. Unfortunately, doing a search for “.bin” files with RealESR (find ~/ | grep -i realesr) did not produce anthing. I’m unsure where/if they are installed, and as such get the complaint from the app that a mising input (the model itself) prevents me from upscaling.
While searching for the model downloads, I came across this project:
https://github.com/nihui/waifu2x-ncnn-vulkan/releases
I downloaded this project, and then ran the app (after accepting all the OSX security questions):
./waifu2x-ncnn-vulkan
Usage: waifu2x-ncnn-vulkan -i infile -o outfile [options]...
-h show this help
-v verbose output
-i input-path input image path (jpg/png/webp) or directory
-o output-path output image path (jpg/png/webp) or directory
-n noise-level denoise level (-1/0/1/2/3, default=0)
-s scale upscale ratio (1/2/4/8/16/32, default=2)
-t tile-size tile size (>=32/0=auto, default=0) can be 0,0,0 for multi-gpu
-m model-path waifu2x model path (default=models-cunet)
-g gpu-id gpu device to use (-1=cpu, default=auto) can be 0,1,2 for multi-gpu
-j load:proc:save thread count for load/proc/save (default=1:2:2) can be 1:2,2,2:2 for multi-gpu
-x enable tta mode
-f format output image format (jpg/png/webp, default=ext/png)
time ./waifu2x-ncnn-vulkan -i ~/Documents/guinea-pig-in-bed.png -s 4 -o ~/Documents/up.png
[0 Apple M1] queueC=0[1] queueG=0[1] queueT=0[1]
[0 Apple M1] bugsbn1=0 bugbilz=0 bugcopc=0 bugihfa=0
[0 Apple M1] fp16-p/s/a=1/1/1 int8-p/s/a=1/1/1
[0 Apple M1] subgroup=32 basic=1 vote=1 ballot=1 shuffle=1
./waifu2x-ncnn-vulkan -i ~/Documents/guinea-pig-in-bed.png -s 4 -o 0.50s user 0.15s system 21% cpu 2.932 total
$ ls -lha ~/Documents/up.png ~/Documents/guinea-pig-in-bed.png
-rw-r--r--@ 1 chrisdawson staff 342K Sep 12 16:25 /Users/chrisdawson/Documents/guinea-pig-in-bed.png
-rw-r--r--@ 1 chrisdawson staff 3.2M Sep 22 10:03 /Users/chrisdawson/Documents/up.png
By far much easier to use than ChaiNNer, and though many might disagree, much preferrable because it is command line. My mind is whirring with the scripting opportunities. Also, while DiffusionBee might take 30 seconds to generate the image, upscaling takes only 3-4 seconds of time (I’m confused about the output on my M1, I think it is not reporting correctly).
 As I experiment with AI/ML, there are always barriers that prevent me from using the software. There are basically three categories for using AI/ML. As a beginner to the space (though not a software newbee), each comes with its own pros and cons.
As I experiment with AI/ML, there are always barriers that prevent me from using the software. There are basically three categories for using AI/ML. As a beginner to the space (though not a software newbee), each comes with its own pros and cons.
- GUI Apps. Download an app. Often it works, sometimes not.
- Local ML Toolkit. Run the ML toolkit locally (use the correct version of python, create an environment, install deps).
- AI Hosted. Run inside Google Colab or HuggingFace or r8.com
- Command line binary. Download a binary like waifu2x, which packages up the code and models (or makes downloading them part of the command line invocation).
GUI Apps: as an example, DiffusionBee is terrific. It works. But, it is limited, and does not support, for example, img2img, nor inpainting. And, not scriptable.
Local ML Toolkit. I’ve been successful at running StableDiffusion, despite my inexperience with Python. But, I’ve been blocked multiple times when I am using instructions because I did not have the correct version of python, or didn’t understand which python environment tool to use (seems there is dissent about whether to use conda or virtualenv, and I’m not familiar enough to understand the intricacies). Or, I was blocked when I couldn’t install a direct dependency using pip, or an indirect dependency like opencv. For example, opencv4 is available in brew, but that is not what Stable Diffusion Infinity (inpainting: https://github.com/lkwq007/stablediffusion-infinity) wants.
AI Hosted. I love Colab and r8.com. And, sometimes the notebooks just don’t work, and I feel less familiar with troubleshooting than if it were my machine.
Command line binaries. I love waifu2x-ncnn-vulkan so far. Runs fast. Scriptable. Prints out the switches for immediate usage.
At any rate, fun toys!